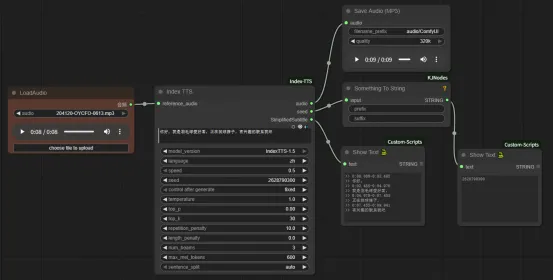
Index TTS
节点功能:该节点用于把输入的文本(text)变成语音(Audio),并输出生成时用到的随机种子(seed)和带有简易时间轴的字幕(SimplifiedSubtitle)。
节点中英文对比
Index TTS
文本内容
/
模型版本
Index-TTS
指定语言
auto
语速
1.0
随机数种子
0
多样性控制
0.1
保留概率前
0.8
概率最高采样
30
惩罚重复生成
10.0
惩罚生成文本长度
0
束宽
3
最大梅尔声谱图
600
句子分割方式
auto
Index TTS
text
/
model_version
Index-TTS
language
auto
speed
1.0
seed
0
temperature
0.1
top_p
0.8
top_k
30
repetition_penalty
10.0
length_penalty
0
num_beams
3
max_mel_tokens
600
sentence_split
auto
Index TTS - 参数说明
输入参数
reference_audio
参考音频,用于提取说话人的音色/风格,使生成语音克隆或相似于此音频。
输出参数
audio
合成语音的音频数据。
seed
随机种子,确定合成时的随机性。相同的参数和种子会生成一致的语音。
SimplifiedSubtitle
附带简易时间轴的字幕文本(对应语音分段)
控件参数
text
要转换成语音的文本内容,支持多行。
model_version
模型版本选择,可选项:Index-TTS: 原始模型版本(默认),IndexTTS-1.5: 新版本模型。
language
指定语音生成的语言,auto: 自动检测语言(默认),zh: 中文,en: 英文。
speed
语速因子(0.5~2.0,默认1.0)。
seed
随机数种子。
temperature
多样性控制(默认1.0, 0.1~1.5),高温度输出更活跃/多变,低温度更“死板”。
top_p
采样时保留概率前p的token(默认0.8, 0.0~1.0),控制生成内容的多样性
top_k
每步只从概率最高的k个token中采样(默认30,1~100),限制结果多样性。
repetition_penalty
惩罚重复生成(默认10.0, 1.0~15.0),数值越大越不容易重复。
length_penalty
惩罚生成文本的长度(默认0, -5.0~5.0),正数生成更短,负数更长。
num_beams
beam search束宽(默认3, 1~10),越大生成越“精细”,速度越慢
max_mel_tokens
最大梅尔声谱图token数(默认600, 100~1500),影响最大音频长度。
sentence_split
句子分割方式(默认auto),auto自动分句,ma-nual需用户分割。